nextgen build infrastructure
Jan. 6th, 2009 11:07 am[brainstorm]:
I keep running into the same questions, project after project, company after company. How do I see who broke the build? How do I know if this bug has been fixed in this codeline? How do I see the difference between these two builds? And how can we make this all happen faster? Smoother? Easier? And you revisit the same questions as new tangles and complexities of scale are added to the equation.
I joined Netscape in 2001, partially to play with a bunch of weird unices, partially to see How Build Engineering is Done Properly. I had already tackled LXR/ViewCVS + Bonsai + Tinderbox elsewhere, and that toolchain has loomed large at every place I've been, at least in concept. Source browsing + repository querying + continuous integration, no matter which specific products you use.
Here I am, back at Mozilla after a number of years away, and I'm amused (and pleased) to see that the current state of things is surprisingly analogous to how I designed our build system elsewhere. We had the db with history and archived configurations; buildbot has the daemon with real-time log views; but otherwise things are fairly close. Both systems are in similar stages of development, ready to take that next step.
Here are some thoughts about the direction that next step could go. Please keep in mind that I'm trying to ignore how much work this will all be to implement for the moment, so I can write down my ideas without cringing.
[Is hgweb a strong bonsai replacement?]:
Installing Bonsai or its equivalent has been my immediate priority for each new project I've joined. Why? It gives you immediate insight into the code base. What's changed. Who's changing it. The full history, across all branches.
I honestly don't see how you manage a large scale CVS project without it. You could manage in Subversion, possibly, but Kamikaze and ViewVC's query database still give you so much more than svn log: cross-repository queries and GUI-user friendliness come to mind.
As for hgweb: it seems to be working for people currently. I can't help but feel like it's missing a lot. I don't claim to be a Mercurial expert by any means. But at first blush:
- How do you differentiate which checkins are in linear history? (Covered here)
- Where's the guilty column? Not sure if this is a missing feature in hgweb or if it's just a matter of needing tinderbox/hg code. But tinderbox used to query bonsai for this info.
- Where are the complex queries? I see you can query by date range in the pushlog, but I haven't found a way to also query by author, bug number, whether the checkin was in linear history or not, and combinations using AND or OR.
- How do I query which repositories bug 12345 has been fixed in? (cross-repo queries)
- Given a query, how do I tell which build first contained a checkin, which build preceded that one, where to get them, and what the delta is between the two builds in terms of code, performance, and unit test results? (cross-system links)
- For that matter, given a query for any two arbitrary checkins in any supported repositor(y|ies), how do we find the above deltas? (cross-repo cross-system links)
Point 4 came up in conversation. We were discussing updating Bugzilla with checkin information, which I've done previously. Adding comments or keywords to a bug is certainly one approach, at the risk of potentially cluttering already-cluttered bugs further. Linking the bug to a Bonsai2/hgweb query that gives you the same information is another. We're still thinking about this one.
Points 5 and 6 depend on a build db, which I'll discuss in more detail shortly.
Whether these features are wanted/needed by the community, and whether desired features are best written into hgweb or an external database like Bonsai's remain to be seen.
[Tinderbox: waterfall vs dashboard]:
Ken Estes had a hard time convincing Netscape to switch to Tinderbox 2, but I felt its modularity and ease of extensibility and customization made it ideal for projects unburdened by the history and existing ingrained processes Moz has. It's great for what it is. As is Tinderbox 1, in its own special way.
Having said that, there are plenty of Tinderbox detractors, and it's hard to defend certain Tinderbox behaviors. Its reliance on procmail, for instance. And it's fairly easy to see how a single waterfall can get overwhelmed with information.
rhelmer covered the current tinderbox/buildbot split, and is among the voices I've heard/read calling for a move away from the waterfall view, which I don't completely understand. I do understand that the waterfall is far from ideal as a solitary view. But it does represent the activity of builds and build machines over a brief amount of time quite well. Even better when you have a guilty column ;-)
So, why not have both? Or multiple? Not to clutter, but to present different ways of accessing the data. Each with their own strengths.
We already have different views. The waterfall is one. Another is the sidebar panel or summary view. But we could add something similar to the Cruise Control and Bamboo dashboard pages. Or create something somewhere in between: collapsible "groups" of builds with ETAs and links to drill down. Customizable per-user views. Graphs of tree-openness over time. Each of these brings something to the table that the others aren't as strong at.
(joduinn points out these cruisecontrol and agitar screenshots)
{kind=link}
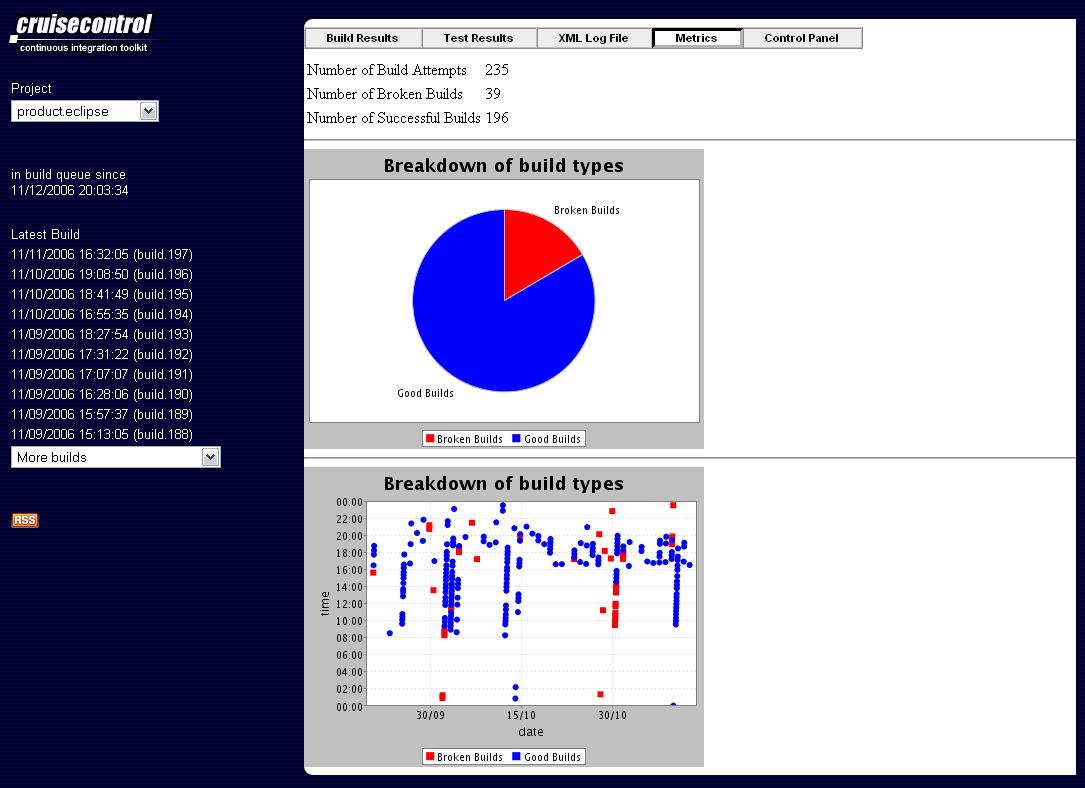{kind=link}
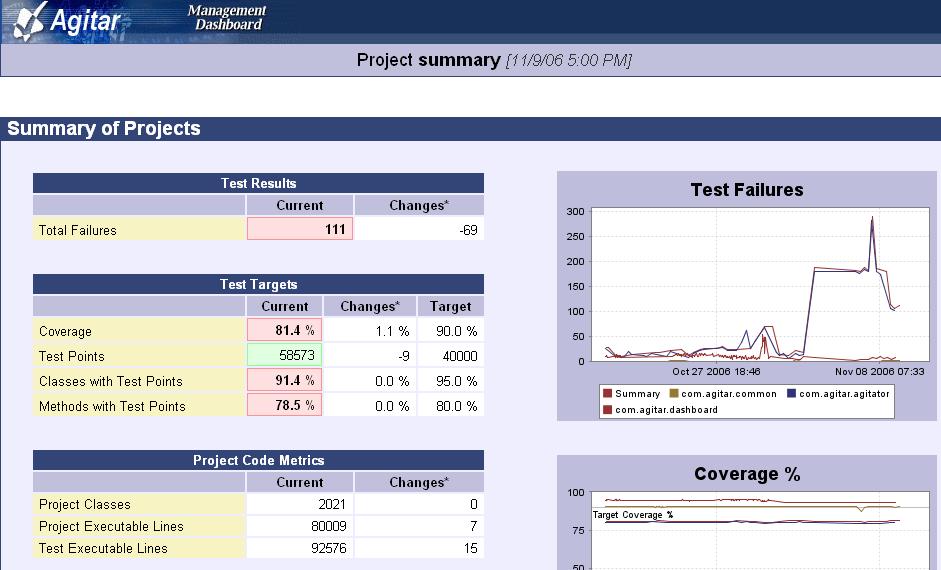{kind=link}
And how do you add a view? Not by putting more load on procmail, certainly. These would be built from build database queries. If we build an anonymous read-only db mirror, or generate the necessary feeds, community members could create their own views.
I saw the hard sell that Ken Estes faced, trying to convince people that something as vital as the Tinderbox waterfall could be changed without altering the Mozilla Way. My solution would be to add views over time, rather than replace them; we can trim if and when old views are no longer wanted/needed.
However, there is that pesky little fact that the build database doesn't exist yet.
[Buildbot: strengths and weaknesses]:
I've only recently started using buildbot. I don't claim to be an expert. Here are my impressions in my brief amount of time using it:
Strengths
- Proven. I believe we're currently running around 270 build slaves across a handful of buildbot masters.
- Host pools. You can specify multiple build machines that are capable of running a particular build. This helps prevent bottlenecks and encourages the creation of a build machine template. This also allows us to take slaves out of the pool for maintenance work without closing the tree.
Queuing. When more changes or requests come than there are build slaves to handle those requests, those builds are queued.
(joduinn amends: When there more change requests than available build slaves, buildbot can be configured to either: queue up those pending builds until a build slave becomes available.... or consolidate all the changes requests into one request in the queue. We currently configure buildbot to consolidate changes, so slaves will never fall too far behind, even if it means in peak periods that mutiple changes are included in the one build.)
- Updates at a single point. There are still host-specific changes (e.g. installing a new SDK), but changes in the build configurations can all be done at the buildbot master.
- Live log views. In its tinderbox waterfall-esque view, you can access logs before the build step finishes, similar to a remote tail -f.
- Sendchange and other build requests. Being able to request a build from a web interface, especially the try server's sendchange patch queue, is a great feature.
Shortcomings
Single point of failure. If the buildbot master goes down, that's it. Everything's dead in the water. We've discussed clustering buildbot, but I think the real answer is a db.
But this is more than just emergency cases. This is also true of routine maintenance or configuration updates. In many cases you can just reconfigure buildbot while it's running. But many times this requires system-wide downtime, whether planned or accidental.
High load on the buildbot master. There is definitely an upper limit to the number of builds than can be run from a single server, and there is no way to tie multiple masters together.
No build slave independence. We've been rebooting our talos slaves as a way to stabilize performance test numbers. We ignore the return value so it doesn't make the build fail, but the slave daemon disconnect keeps showing up red or purple in the buildbot waterfall.
I envision occasional maintenance steps: after X number of builds, do some disk cleanup, defragmentation, reboot, without false positive errors. I also envision setting multiple masters in the build slave config, for both load balancing and failover. The build slaves, for the most part, are smart enough to run Python. They should be allowed to run some steps without a full-time server/client leash, as long as the appropriate server can query status. And it shouldn't matter whether the server that initiated the build request is the same that takes the final results, as long as the appropriate failover occurred.
Limited views and history querying. Database.
(joduinn points out: Scrolling back in a waterfall doesnt work for this, especially whenever timestamps dont line up, or when items start to fall off the bottom of the page. Waterfall also does not work for "when did this intermittent test last fail" - a common question. Letting people roll their own SQL query / plugin / easy-to-use web UI / firefox addon, seems better for both of these usage cases.)
Loss of state. Build queues are kept in memory. Downtime not only means kililng running builds, but also clearing any queued builds.
Splitting out the queuing step to a specifiable object would work; drop in an object that saves the queue to disk, or send it to the database.
Single config. This could be seen as a feature or a bug. I tend to favor picking up build config/script changes automatically from source, which helps preserve history of which config was used in which build.
I haven't really fully fleshed this one out. Spawning multiple buildbot/twistd processes, much like httpd, to allow old-config builds to complete. Or having a multiple brief .cfg files checked in to help make changes more granular. This will take a bit more exploration. But updates from source per build would be nice.
[Pull, not push]:
During one of my interviews for Mozilla, I covered build database architecture. I pretty much covered what I had already planned and [mostly] implemented elsewhere, and the designs matched perfectly, except for one thing.
Buildbot pushes queued builds to its slaves via twisted. I took a similar approach independently, using sshd; when a single server coordinates everything, it's fairly easy to take the push model. But during the interview, I was asked specifically about pulls.
Overall, same thing, right? Pushing from a central server, or having multiple servers pull from a central queue.
Except if you pull from a central queue, rather than push from that queue, you remove your dependence on a single build server knowing everything. The database becomes central, but there are already established ways of mirroring those.
After thinking about this for a while, I thought why not? Two or five servers queuing builds, each able to take over the others' responsibilities if needed. Three or ten servers pulling builds from the queue, managing distributed build farms, each able to take over others' builds and build clients if one or more servers were to go down. The database is the central thing, not any instance of buildbot. And all the configs are in source.
The queuers could also do routine maintenance: act on stalled builds, determining status and requeuing or failing out as necessary. Inserting maintenance tasks as needed into host pools, but without taking too many build hosts out of any one pool at any time.
With this model, I would guess -- not promise or guarantee, but strongly guess -- we could scale up by an order of magnitude. Add quote-unquote buildbot masters as queuers or build coordinators as needed. Different groups could have their own sets if needed or desired. And if the db became the bottleneck, I imagine we could find ways to logically split it up.
I've never seen a build system anywhere near that scalable. Except in my head. But it's exciting to think.
[Still a ways out]:
I've been expounding on some of my ideas about what we could potentially do with a build db... which doesn't exist yet. It may take a while.
I think the first step is to be able to dump queues to disk, possibly in yaml, possibly in python, and be able to read those queues back into buildbot at start. Then add a module that lets us queue to disk by default. Hopefully during the process we can reduce the amount of information in the request to the bare bones: revision, requester, build type, time of request, etc., and separate it from the actual build logic.
I'm not quite used to working by announcing plans or ideas in public before they're implemented; even at NSCP we tended to keep things in-house unless they were Mozilla-specific. Hopefully some of these ideas resonate with other people as well; let me know. And hopefully people can wait a bit if they really want some of these ideas implemented.
... Back to work on the Nokias and try server.
hgweb
Date: 2009-01-06 08:48 pm (UTC)Especially it provides a lot faster blame (when comparing to hgweb annotate).
Re: hgweb
Date: 2009-01-06 09:05 pm (UTC)no subject
Date: 2009-01-06 10:49 pm (UTC)Re tinderbox and build db, I'd point you to my post on http://blog.mozilla.com/axel/2008/12/19/working-demo-waterfall-and-more/. Build db is there, as are at least one additional view (builds for change). That db can be shared among masters, with views spanning build reports from multiple masters. Build logs still requires some upstream buildbot patches to be written.
The difference between pull and push: Pull requires config on the slave, push requires config on the master. While the master configs get slightly out of hand, and the master is becoming a single point of failure, the slaves are the hardware that actually needs to scale, as long as the master is written OK, for the most part. I.e., no blocking network connections on the master and such. So making the slaves dumb and easy to set up is a winner here.
I don't think that being able to restore pending builds on master maintainance is a biggie, as long as one can actually just kick the missing builds by hand. That isn't all to hard to do, on my buildbot instance on the l10n server, I have even custom interfaces to trigger a flock of builds on demand.
What's missing here in my view is a way to take slaves out of the rotation without just killing them. That's probably a good step towards adding load balancing to buildbot, so if someone came up with a patch refactoring that code so that it can be replaced with some custom implementation (talking to a web site controlled db, for example), that would probably be easy to get upstream.
no subject
Date: 2009-01-06 11:15 pm (UTC)I'll take a look at your blog; glad to see there's been work done in that direction.
Dumb slaves: I don't want to make them too independent, just able to detach from the master for certain steps. Maybe include a reboot as a mid-build step (as long as they restart buildbot on boot), or a way to pass multiple steps in advance. In this model, the pulling would be done by buildbot masters from a central queue or pool of queues.
Restoring queues and not killing builds during master maintenance could help keep us from closing the tree for such purposes, as long as there are other buildbot masters to pick up the builds.
But certainly, I'll take a look at what you've already done. Thanks for your comment!
no subject
Date: 2009-01-06 11:27 pm (UTC)This is a tad funky to set up right now, and I don't have a good daemon updating the database so far, thus it's not running anywhere but on my local machine, updated when I need it.
no subject
Date: 2009-01-06 11:35 pm (UTC)no subject
Date: 2009-01-07 02:35 pm (UTC)About hgweb:
"How do you differentiate which checkins are in linear history"
We've been working on addressing this. I think we're not really there yet, but we're a lot better than we used to be. You can query the pushlog by date: http://hg.mozilla.org/mozilla-central/pushloghtml, but I also added the changeset to about:buildconfig, so you can link back to the exact source your copy of Firefox was built from. Granted, that still doesn't quite answer the question, "Is this checkin in my build?"
"Where's the guilty column?"
We've got bug 419949 on file for this. Essentially, our hg repositories are completely decoupled from bonsai, so Tinderbox has no idea where to get this data from. The pushlog provides an ATOM feed (which is precisely what buildbot is polling for changes), but the unhackability of Tinderbox has made this dead in the water so far.
"Where are the complex queries? I see you can query by date range in the pushlog, but I haven't found a way to also query by author, bug number, whether the checkin was in linear history or not, and combinations using AND or OR"
Some combination of "not implemented" and "not exposed in the UI". You can query by user:
http://hg.mozilla.org/mozilla-central/pushloghtml?startdate=2+weeks+ago&enddate=now&user=tmielczarek@mozilla.com but that's not in the UI. Bug number is trickier, as there isn't really any mapping there, unless you just want to search the commit messages. I'm not sure what you mean by "whether the checkin was in linear history or not".
"How do I query which repositories bug 12345 has been fixed in? (cross-repo queries)"
I don't even know how you'd query whether bug 12345 was fixed in mozilla-central, since the only mention of bug numbers is free-form text in the commit message. But yeah, currently you can't do any queries cross-repo. I can't say I've heard anyone else ask for this feature, to be honest.
As you've already said, for the latter two points, we'd need some sort of build db. We've discussed this in passing before, how it would be nice to have a simple webapp that listed the changesets that each nightly was based off of, since it's really not hgweb's business to track what we build out of the repository.
As Axel points out in his comment, he added a really nice JSON output to the pushlog, so it's pretty low-effort to get data out of there to test things out, which I think is really nice. In fact, I think having very good ways to get the data out of our webtools will let us prototype things in mashup form a lot faster, and help us get to where we need to be sooner.
-Ted
no subject
Date: 2009-01-07 06:10 pm (UTC)Tinderbox2 is a lot more modular, but I think the larger question will become whether we keep Tinderbox or switch to a buildbot waterfall + other views.
Complex queries: I suppose just showing the revision that matches the query, and the revision where it lands in linear history (if different) would satisfy "whether the checkin was in linear history or not".
Cross-repo queries: I think these will become more important when we start getting security releases off hg repos, and we need to find which codebases have a specific security fix. Or maybe people don't really need this.
But it's good to hear that a lot of progress is being made. I certainly don't expect to see all of these requests/ideas implemented immediately; I'd actually be surprised to see all the wanted points implemented before a year or two pass.
no subject
Date: 2009-01-07 07:52 pm (UTC)As for querying comments, that's tricky. I experienced bad problems with have free form text, unicode and indexing for mysql. Basically, it just indexes the first 333 chars. Comments don't need to be unique, where it actually dies, so maybe this isn't that much of a problem. That said, I don't know if there's an efficient storage inside .hg for searching for comments already, so maybe duplicating that in an external db wouldn't help much.
~Axel
no subject
Date: 2009-01-08 04:39 am (UTC)Now that I've turned off brainstorm mode, the sheer amount of work that a lot of this entails is sinking [back] in, and I certainly understand if this isn't all implemented immediately (or at all).