|
preface Since I wrote my previous blog post on LWR, I've found/been sent/been reminded of a few links:
I'm going to keep writing this third LWR blog post as planned, since I think we failed to explain things clearly to our newer team members during the team week. Also, recording our recent brainstorming may help us decide if these other scheduling systems would work for us, and help guide any customizations we may want to make, should we choose to use them. |
|
whiteboard schematics 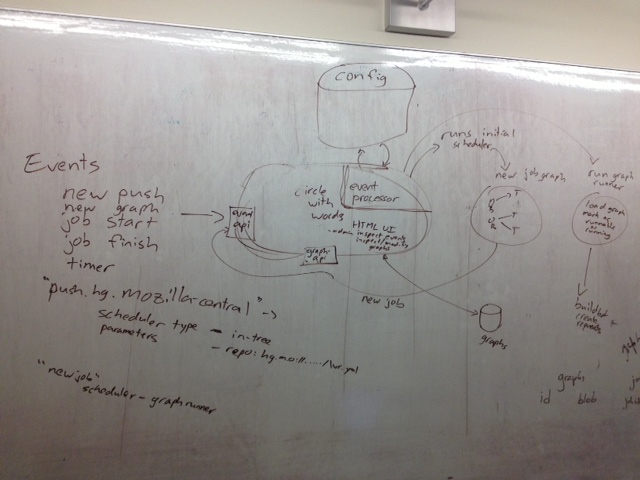 the drawing is either really important, or just a brainstorm first draft. i'm not sure which yet.
We'd like to keep the server-side as dumb as possible. The fewer changes that need to be made there, the more stable it will be. By moving logic and configs off the server, we can make more complex and granular changes without touching the servers. We've already seen the effects of keeping all the logic, all the configs, all the scheduling on the buildbot masters, and we want the opposite. We'd like a small server to be runnable on a single machine, so we can test and debug changes on our laptops. Versioned- or backwards-compatible APIs may allow us to upgrade half a production cluster, bring that live, then upgrade the second half. If we're easily able to spin up a new standalone cluster, we can easily support different workflows/audiences like staging-vs-production, standalone project branch "pods", or experimental small project support. |
|
slaveapi, mozpool, and network logging Currently, buildbot has a list of buildslaves per builder, and keeps track of which ones are currently connected to the buildbot master. :catlee then tweaks the nextSlave logic to prefer faster buildslaves over slower, or spot instances over reserved instances (or to use reserved instances if the same job was run on an interrupted spot instance), or the last buildslave that successfully ran that particular job (to improve depend build times). Buildbot doesn't have any concept of how healthy the buildslave is, or how to maintain the buildslaves, and requires that we make any pooling or nextSlave decisions ahead of time and load them into the running buildbot masters via a reconfig. Plus, the master<->buildslave communication requires an uninterrupted network connection, which gives us streaming logs, but adds network fragility. SlaveAPI is designed to handle some of the above issues: determine the health of a slave, reboot a slave, or mark it as disabled. In the future it may allow us to spin up and spin down AWS instances, and reimage hardware slaves. MozPool is currently limited to Android Pandas, and allows for health checks on Pandas, rebooting Pandas, and IIRC reimaging Pandas. A job that requires a Panda would be able to request [a healthy] one from the pool, run the job, and return it to the pool or mark it as bad. With a combination of the two, LWR could request a node with certain properties (with tags, maybe?): any machine; any linux/osx machine; the fastest linux machine available with build tools; or specifically by hostname. If LWR also passed the history and details of the job along with the request, the SlaveAPI/MozPool analog could make decisions like spot instance or reserved instance; fast or slow; most recently successfully built that tree so a depend build would be fast. And we might be able to keep that complexity out of LWR. We'd like to be able to spawn the job and detach, to remove the need for an uninterrupted network connection. For status, it might be nice to be able to tail the log on demand, and/or add network logging support to mozharness (via a MultiNetworkLogger class, perhaps). This would probably require a network log cluster of some sort. Someone else suggested that we be able to toggle the network logging on at will, but otherwise default to off, to reduce network traffic. I'm not entirely sure how to do this, but given a trigger we could replay the log from disk over the network, and continue to stream the log as it came in, once the network logging had caught up. We could also take this opportunity to move away from the buildbot master/slave terminology, to... perhaps server/node? farmer/cow? :) Technically this wouldn't matter at all. Semantically it does. |
|
artifact manifests Currently, we upload various things from build jobs: installers, crashsymbols, test zips. The build jobs then guess which binary is the installer and sendchange the installer and test zip urls, triggering tests. The buildbot master then uploads the build logs, sometimes to a completely different directory than the installer, which can cause issues with TBPL and other downstream consumers. The test jobs take the installer and test zip urls from the sendchange, and use those to download and install the binary, extract the tests, and run them. Sometimes they need other files: crashsymbols, the robocop apk, so we apply a regex to the installer url to guess the other urls, causing all sorts of fun when this doesn't work. In a similar vein, we download previous MARs to generate partial updates. However, the mar files contain version numbers, causing more fun when we try to guess the filename after a version bump. Call me a buzzkill, but I'd like to eliminate all this fun guesswork in favor of a boring and predictable solution. I'd like an artifact manifest. A structured artifact manifest, with versioned manifest formats, so we know how to read them. And while I think it's ok to have a section of the manifest for dumping random blobs of information, if portions of those become generally useful, we should probably put those in the structured area in the next version of the manifest format. The manifest would definitely contain naming information for the various artifacts uploaded, as well as what they are. If mozharness jobs uploaded their own logs, they would more predictably live with the other artifacts, and be specified in the manifest. We could also include job status and uid and other such information. Dependent jobs could then act on all of that information without guessing, given only the location of the manifest. This also reduces the amount of information that LWR has to transfer between jobs... and may satisfy :sfink's request for more structured schema for downstream jobs. |
|
phase one We can't write and roll all of this out at once. Besides the magnitude of work represented by this handful of blog posts, we also have existing dependencies on buildbot that we don't yet have replacements for. For phase one, we're picturing the graph processing pool sending jobs into buildbot, probably via the db. First we should build the dependency graph for our existing build and test jobs. If I were to tackle one piece first, this would be it, because it's a single script with no infrastructure dependencies. It's easy to verify afterwards, by comparing the output to our existing TBPL runs. Normalizing the builder names would help here. Then we could feed that graph into self serve, potentially allowing us to more easily trigger individual builds (we currently use regexes, iirc). Tests and repacks may be trickier, since they expect additional information to come via sendchange and buildbot properties, but that's a start. Next we could start writing the server pieces -- trigger polling, graph generation, iterate through the graph. Any web app work could start here. This isn't strictly blocked by the self-serve implementation, so if more people chipped in we could work on those in parallel. We could then start feeding the jobs from the graph into buildbot, and disable the respective buildbot polling and scheduling. Once we got this far, we could also look into moving certain jobs that are already ported to mozharness out of buildbot and into a pure LWR implementation. That may depend on a streaming log solution or artifact manifest solution. This might belong in phase 2. |
I've been both excited and nervous writing about LWR. Excited, since I'm bursting with ideas for the project. Nervous, because so much of it extends outside of my domain of expertise; because it's a huge project; because portions of it are still nebulous concepts in my head. I think we have the team(s) to build it, though. And since I think best about projects when I write [about] them, these blog posts have helped focus my ideas. To get a first draft down that we can revise later.
In part 1, I covered where we are currently, and what needs to change to scale up.
In part 2, I covered a high level overview of LWR.
In part 4, I'm going to drill down into the dependency graph.
Then I'm going to meet with the A-team about this, and start writing some code.